SEO
What is Robots.txt File? What are the Different types of bots or Web Crawlers?
Robots.txt is a standard text file is used for websites or web applications to communicate with web crawlers (bots). It is used for the purpose of web indexing or spidering. It will help the website that ranks as highly as possible by the search engines.

Table of Contents
1. What is robots.txt?
Robots.txt is a standard text file that is used for websites or web applications to communicate with web crawlers (bots). It is used for web indexing or spidering. It will help the site that ranks as highly as possible by the search engines.
The robots.txt file is an integral part of the Robots Exclusion Protocol (REP) or Robots Exclusion Standard, a robot exclusion standard that regulates how robots will crawl the web pages, index, and serve that web content up to users.
Web Crawlers are also known as Web Spiders, Web Robots, WWW Robots, Web Scrapers, Web Wanderers, Bots, Internet Bots, Spiders, user-agents, Browsers. One of the most preferred Web Crawler is Googlebot. This Web Crawlers are simply called as Bots.
The largest use of bots is in web spidering, in which an automated script fetches, analyzes, and files information from web servers at many times the speed of a human. More than half of all web traffic is made up of bots.
Many popular programming languages are used to created web robots. The Chicken Scheme, Common Lisp, Haskell, C, C++, Java, C#, Perl, PHP, Python, and Ruby programming languages all have libraries available for creating web robots. Pywikipedia (Python Wikipedia bot Framework) is a collection of tools developed specifically for creating web robots.
Examples of programming languages based open-source Web Crawlers are
- Apache Nutch (Java)
- PHP-Crawler (PHP)
- HTTrack (C-lang)
- Heritrix (Java)
- Octoparse (MS.NET and C#)
- Xapian (C++)
- Scrappy (Python)
- Sphinx (C++)
2. Different Types of Bots
a) Social bots
Social Bots have a set of algorithms that will take the repetitive set of instructions in order to establish a service or connection works among social networking users.
b) Commercial Bots
The Commercial Bot algorithms have set off instructions in order to deal with automated trading functions, Auction websites, and eCommerce websites, etc.
c) Malicious (spam) Bots
The Malicious Bot algorithms have instructions to operate an automated attack on networked computers, such as a denial-of-service (DDoS) attacks by a botnet. A spambot is an internet bot that attempts to spam large amounts of content on the Internet, usually adding advertising links. More than 94.2% of websites have experienced a bot attack.
d) Helpful Bots
The bots will helpful for all customers and companies and make Communication over all the Internet without having to communicate with a person. for example, e-mails, chatbots, and reminders, etc.

3. List of Web Crawlers or User-agents
List of Top Good Bots or Crawlers or User-agents
Googlebot
Googlebot-Image/1.0
Googlebot-News
Googlebot-Video/1.0
Googlebot-Mobile
Mediapartners-Google
AdsBot-Google
AdsBot-Google-Mobile-Apps
Google Mobile Adsense
Google Plus Share
Google Feedfetcher
Bingbot
Bingbot Mobile
msnbot
msnbot-media
Baiduspider
Sogou Spider
[/php]
YandexBot
Yandex
Slurp
rogerbot
ahrefsbot
mj12bot
DuckDuckBot
facebot
Facebook External Hit
Teoma
Applebot
Swiftbot
Twitterbot
ia_archiver
Exabot
Soso Spider
[/php]
List of Top Bad Bots or Crawlers or User-agents
dotbot
Teleport
EmailCollector
EmailSiphon
WebZIP
Web Downloader
WebCopier
HTTrack Website Copier/3.x
Leech
WebSnake
[/php]
BlackWidow
asterias
BackDoorBot/1.0
Black Hole
CherryPicker
Crescent
TightTwatBot
Crescent Internet ToolPak HTTP OLE Control v.1.0
WebmasterWorldForumBot
adidxbot
[/php]
Nutch
EmailWolf
CheeseBot
NetAnts
httplib
Foobot
SpankBot
humanlinks
PerMan
sootle
Xombot
[/php]
Note:- If you need more names of Bad Bots or Crawlers or User-agents with examples in the TwinzTech Robots.txt File.
4. Basic format of robots.txt
[php]
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
[/php]
The above two lines are considered as a complete robots.txt file. one robots file can contain multiple lines of user agents names and directives (i.e., allows, disallows, crawl-delays, and sitemaps, etc.)
It has multiple sets of lines of user agent’s names and directives, which are separated by a line break for an example in the below screenshot.

Use # symbol to give single line comments in robots.txt file.
5. Basic robots.txt examples
Here are some regular robots.txt Configuration explained in detail below.
Allow full access
[php]
User-agent: *
Disallow:
OR
User-agent: *
Allow: /
[/php]
Block all access
[php]
User-agent: *
Disallow: /
[/php]
Block one folder
[php]
User-agent: *
Disallow: /folder-name/
[/php]
Block one file or page
[php]
User-agent: *
Disallow: /page-name.html/
[/php]
6. How to create a robots.txt file
Robots files are in text format we can save as text (.txt) Formats like robots.txt in editors or environments. See the example in the below screenshot.
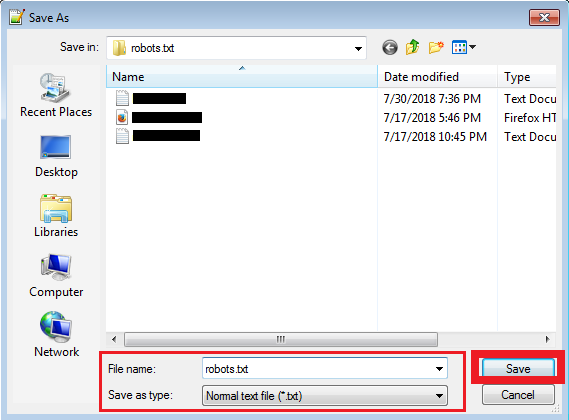
7. Where we can place or find the robots.txt file
The website owner wishes to give instructions to web robots. They place a text file called robots.txt in the root directory of the webserver. (e.g., https://www.twinztech.com/robots.txt)
This text file contains the instructions in a specific format (see examples below). Robots that choose to follow the instructions try to fetch this file and read the instructions before fetching any other file from the website. If this File doesn’t exist, web robots assume that the web owner wishes to provide no specific instructions and crawl the entire site.
8. How to check my website robots.txt on the web browser
Go to web browsers and enter the domain name in the address bar of the browser and add forward slash like /robots.txt and enter and see the file details (https://www.twinztech.com/robots.txt). See the example in the below screenshot.

9. Where we can submit a robots.txt on Google Webmasters (search console)
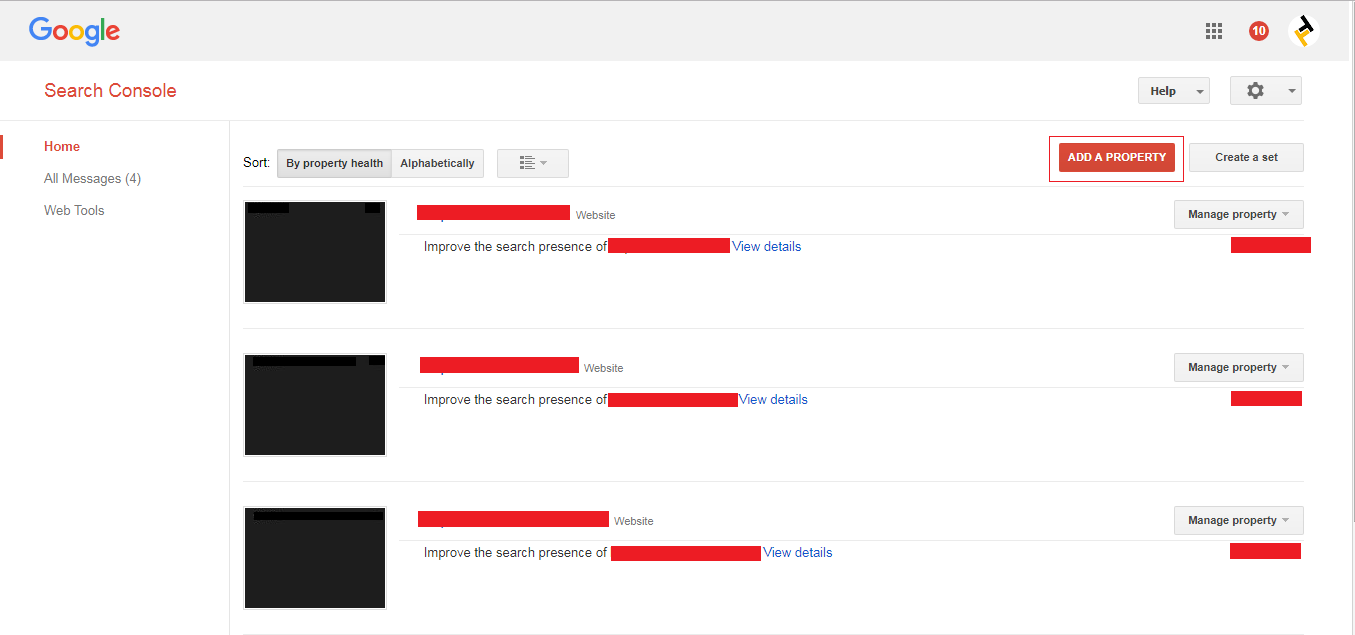
Follow the below example screenshots and submit the robots.txt on webmasters (search console).
1. Add a new site property on search console-like as below screenshot (if you have a property on search console leave the first point and move to second).
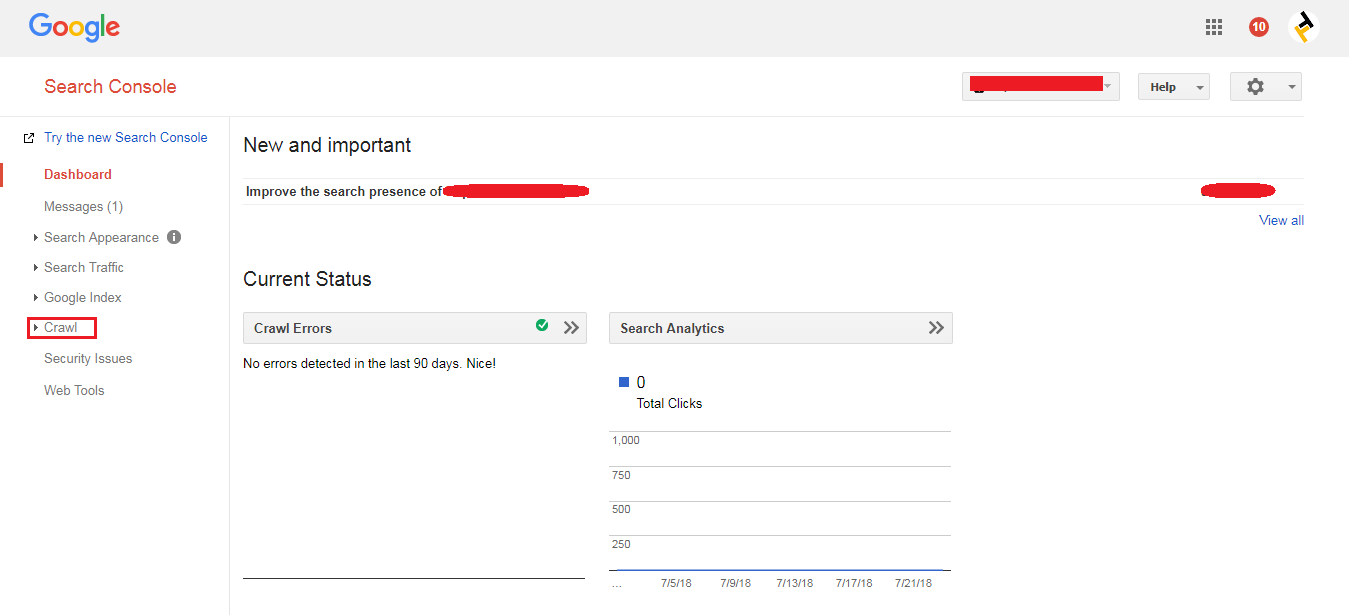
2. Click your site property and see the new options on screen and select the crawl options on the left side is as shown in the below screenshot.
3. Click the robots.txt tester option in crawl options is as shown in the below screenshot.
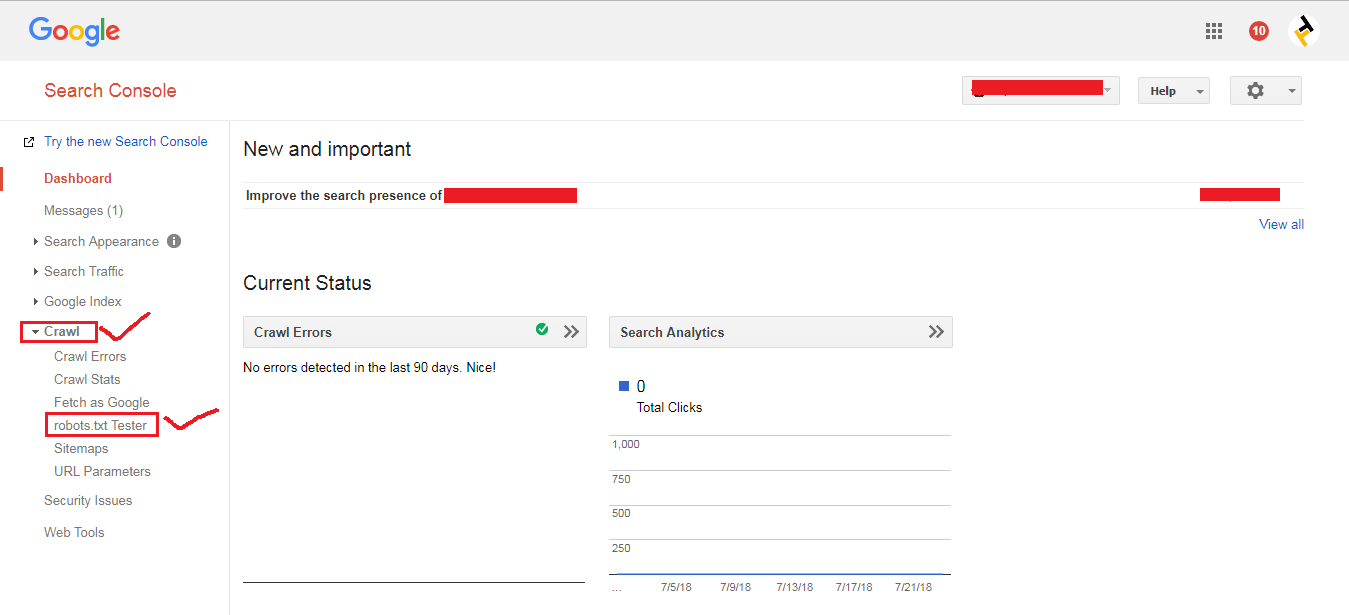
4. After clicking the robots.txt tester option in crawl options, we can see the new options on screen and click the submit button is as shown in the below screenshot.
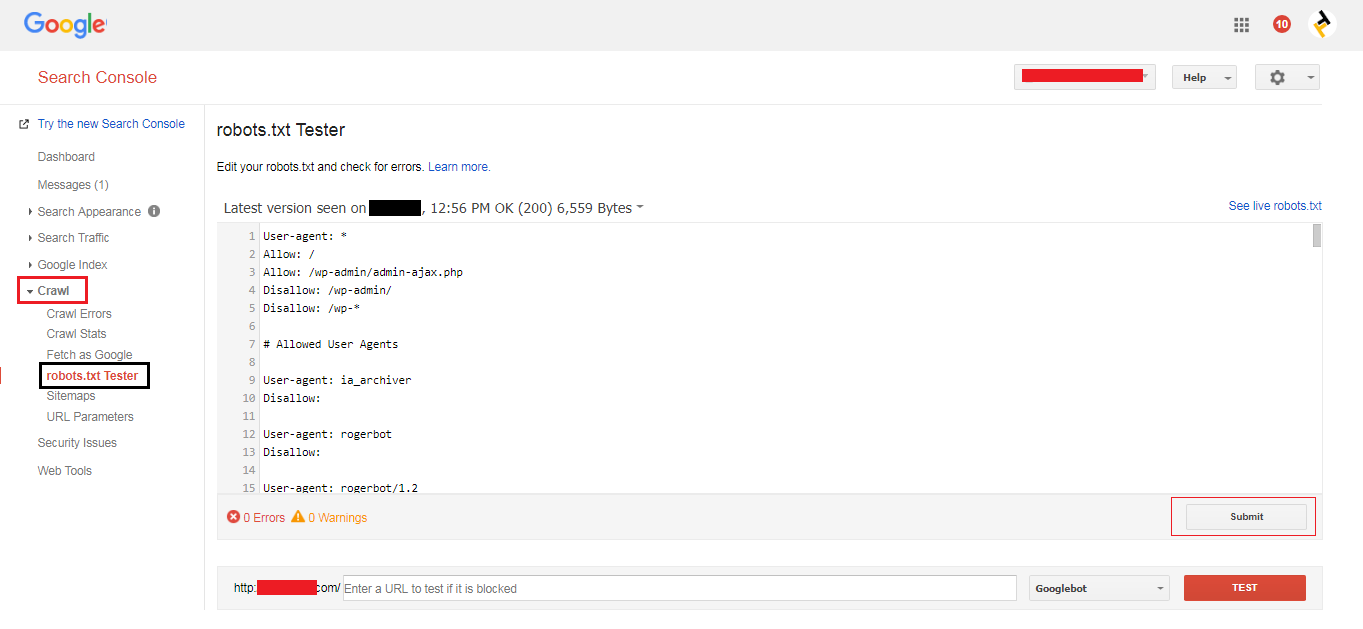
10. Examples of how to block specific web crawler from a specific page/folder
[php]
User-agent: Bingbot
Disallow: /example-page/
Disallow: /example-subfolder-name/
[/php]
The above syntax tells only Bing crawler (user-agent name Bingbot) not to crawl the page that contains the URL string https://www.example.com/example-page/ and not to crawl any pages that contain the URL string https://www.example.com/example-subfolder-name/.
11. How to allow and disallow a specific web crawler in robots.txt
[php]
# Allowed User Agents
User-agent: rogerbot
Allow: /
[/php]
The above syntax tells to Allow the user-agent name called rogerbot for crawling/reading the pages on the website.
[php]
# Disallowed User Agents
User-agent: dotbot
Disallow: /
[/php]
The above syntax tells to Disallow the user-agent name called dot bot for not crawling/reading the pages on the website.
12. How To Block Unwanted Bots From a Website By Using robots.txt File
Due to security we can avoid or block unwanted bots using the robots.txt file. The List of unwanted bots is blocking by the help of robots.txt File.
[php]
# Disallowed User Agents
User-agent: dotbot
Disallow: /
User-agent: HTTrack Website Copier/3.x
Disallow: /
User-agent: Teleport
Disallow: /
User-agent: EmailCollector
Disallow: /
User-agent: WebZIP
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: Leech
Disallow: /
User-agent: WebSnake
[/php]
The above syntax tells to Disallow the unwanted bots or user-agents names for not crawling/reading the pages on the website.
See the below screenshot with examples

13. How to add Crawl-Delay in robots.txt file
In the robots.txt file, we can set Crawl-Delay for specific or all bots or user-agents
[php]
User-agent: Baiduspider
Crawl-delay: 6
[/php]
The above syntax tells Baiduspider should wait for 6 MSC before crawling each page.
[php]
User-agent: *
Crawl-delay: 6
[/php]
The above syntax tells all user-agents should wait for 6 MSC before crawling each page.
14. How to add multiple sitemaps in robots.txt file
The examples of adding multiple sitemaps in the robots.txt file are
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/post-sitemap.xml
Sitemap: https://www.example.com/page-sitemap.xml
Sitemap: https://www.example.com/category-sitemap.xml
Sitemap: https://www.example.com/post_tag-sitemap.xml
Sitemap: https://www.example.com/author-sitemap.xml
The above syntax tells us to call out multiple sitemaps in the robots.txt File.
15. Technical syntax of robots.txt
There are five most common terms come across in a robots file. The syntax of robots.txt files includes:
User-agent: The command specifies the name of a web crawler or user-agents.
Disallow: The command giving crawl instructions (usually a search engines) to tell a user-agent not to crawl the page or URL. Only one “Disallow:” line is allowed for each URL.
Allow: The command giving crawl instructions (usually a search engines) to tell a user-agent to crawl the page or URL. It is only applicable for Googlebot.
Crawl-delay: The command should tell how many milliseconds a crawler (usually a search engines) should wait before loading and crawling page content.
Note: that Googlebot does not acknowledge this command, but crawl rate can be set in Google Search Console.
Sitemap: The command is Used to call out the location of any XML sitemaps associated with this URL.
Note: This command is only supported by Google, Ask, Bing, and Yahoo search engines.
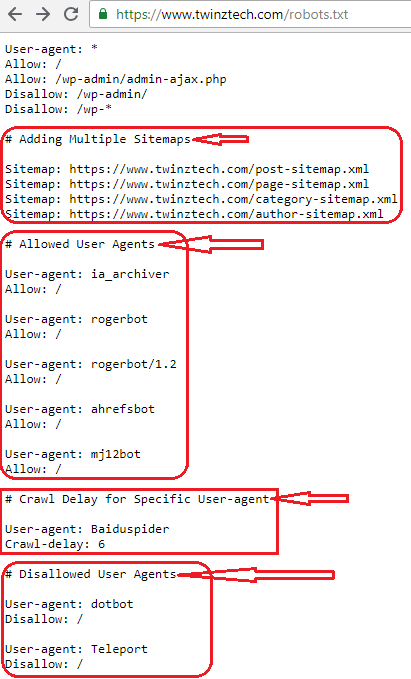
Here we can see the Robots.txt Specifications.
Also Read : How to Flush the Rewrite URL’s or permalinks in WordPress Dashboard?
16. Pattern-matching in robots.txt file
All search engines support regular expressions that can be used to identify pages or subfolders that an SEO wants excluded.
With the help of Pattern-matching in the robots.txt File, we can control the bots by the two characters are the asterisk (*) and the dollar sign ($).
1. An asterisk (*) is a wildcard that represents the sequence of characters.
2. Dollar Sign ($) is a Regex symbol that must match at the end of the URL/line.
17. Why is robots.txt file important?
Search Engines crawls robots.txt File first, and next to your website, Search Engines will look at your robots.txt File as instructions on where they are allowed to crawl or visit and index or save on the search engine results.
Robots.txt files are very useful and play an important role in the search engine results; If you want search engines to ignore or disallow any duplicate pages or content on your website do with the help of robots.txt File.
Helpful Resources:
1. What is the Difference Between Absolute and Relative URLs?
2. 16 Best Free SEO WordPress plugins for your Blogs & websites
3. What is Canonicalization? and Cross-Domain Content Duplication
How AI Is Reshaping Digital Marketing Strategies in 2026

Maximizing ROI with HCI: Real‑World Benefits for IT Leaders

Search Atlas: What the Platform Does and Why It Leads in Local SEO
How Alert Fatigue Is Increasing Cyber Risk

How Apps Can Make Employee Communication A Lot More Simple

The Global Awakening: Understanding Gen Z’s Voice 🌍🎤

Canva AI: Your Creative Co-Pilot, Explained 🎨🤖

DALL·E AI: Redefining Creativity with Artificial Intelligence 🎨🤖

Runway ML: The Future of AI-Powered Creativity 🎥✨

🎨 Midjourney: The Complete Guide to AI Art Generation in 2025
Buy IG likes and buy organic Instagram followers: where to buy them and how?

100% Genuine Instagram Followers & Likes with Guaranteed Tool

7 Must Have Digital Marketing Tools For Your Small Businesses
Instagram Followers And Likes – Online Social Media Platform

Use of 3D Printing in Injection Molding
Top 25 Best SolarMovie Alternatives Updated List

13377x Original Site: 1337x Official Site, Proxy Sites, Movies, Torrents

Principles of Good Software Engineering

How To Get Started With Artificial Intelligence

Tamilrockers Alternatives: TamilRockers Proxy and Mirror Sites [working]
-
Instagram5 years ago
Buy IG likes and buy organic Instagram followers: where to buy them and how?
-
Instagram5 years ago
100% Genuine Instagram Followers & Likes with Guaranteed Tool
-
Business7 years ago
7 Must Have Digital Marketing Tools For Your Small Businesses
-
Instagram6 years ago
Instagram Followers And Likes – Online Social Media Platform