Google Search Console
What is Canonicalization? and Cross-Domain Content Duplication
Canonicalization is the process of avoiding duplicate content on websites pages. A canonical tag is a way of telling search engines that a specific URLs represents the original copy of a page.

Due to content duplication search engines demote your websites. we can lose website traffic because of duplicate content and how to get back our traffic and avoiding duplicate content by using link tag with the rel=”canonical” attribute.
The link tag with the rel=”canonical” attribute avoid whole page “Duplicate Content” and “cross-domain content duplication“.
Table of Contents
1. Canonicalization
If your site contains multiple pages with largely identical content, there are a number of ways you can indicate your preferred URL to Google This is called “canonicalization“.
Canonicalization is the process of avoiding duplicate content on websites pages. A canonical tag is a way of telling search engines that specific URLs represent the original copy of a page. If the website has similar or duplicate pages, Consolidate duplicate URLs define with the help of the canonical link tag element.
Before cross-domain rel=”canonical” link element, Google introduced two meta tags called syndication-source and original source. These tags were designed to avoid content duplication on website pages. After introducing the rel=canonical tag, google had been depreciated the above meta tags.
In the year of 2009, Google has announced and its support for using the rel=”canonical” link element across different domains.
Google, Yahoo, Microsoft, and Ask have announced to offer a way to reduce cross-domain content duplication and make things easier for everyone.
With the help of rel=canonical tag, bots can easily understand which one is the original and duplicate content on website pages.
Canonical Tag Representation Code Example:

The rel=”canonical” tag is an HTML attribute that action to indicates the page on which the tag appears should be treated as a duplicate of the specific URL.
2. The main problem with URLs
Google tries hard to index and show pages with distinct information. Google can assume the website URLs split or separate in multiple variations. It Consolidates duplicate URLs. For example, search bots or crawlers may be able to reach your site homepage in all of the following ways. Here is a list of all URL variations that the site would be likely visible as follows.
- https://www.yourdomain.com/
- http://www.yourdomain.com/
- https://yourdomain.com/
- http://yourdomain.com/
- https://www.yourdomain.com
- http://www.yourdomain.com
- https://yourdomain.com
- http://yourdomain.com
- https://www.yourdomain.com/index.html
- http://www.yourdomain.com/index.html
- https://yourdomain.com/index.html
- http://yourdomain.com/index.html
Modern dynamic websites and content management systems (CMS) are facing more problems. Many websites automatically add tags, allow multiple paths or URLs to the same content, and also add URL parameters to the searches, filtering sorts, and currency-related options. we can’t realize it but your websites have thousands of duplicate URLs.
3. What is Duplicate Content?
Duplicate content is content that appears on the many places or many web pages or across domains on the Internet. search engines can crawl URLs with identical or similar content on multiple URLs, it may cause the number of SEO problems.
Search engines will choose any one URL version to serve, which may not always be the original or best one. Search engines don’t know which version to either include or exclude from their indexes.
Why would I have similar or duplicate pages?
In dynamic web applications and Modern CMS, the content or data (blog articles) on a website will automatically appear on different Page URLs based on the dynamic functionality of the websites that’s why the Google or any search engines should be considered as duplicate or copy content means similar or duplicate pages. Every dynamic page should have similar or duplicate pages based on the dynamic functionality basics.
4. Consolidate duplicate URLs
If the website has multiple URLs or different pages with similar or duplicate content on both a mobile and a desktop version, Google will consider as duplicate versions of the same page. It will choose any one URL as the canonical version and crawl that, and remaining all URLs will be considered as duplicate URLs and crawled frequently.
If you don’t specify, to tell Google which URL is canonical, It will choose for you or may consider them both of equal value, which may guide to unwanted behavior, and we are explained below about Why should I choose a canonical URL?
5. Why should I choose a canonical URL?
Google or any other search engine doesn’t like duplicate content that is not unique so. When a duplicate or Non-Original content is present on Your Site Will Hurt Your Rankings and traffic losses across Your Domain.
If your site contains multiple pages with largely identical content, you should use the canonical tag to your site pages to avoiding duplicate content. If you are not using a canonical tag, the site will lose rankings and traffic, and sometimes they would downgrade a website for having a lot of duplicates or copy content.
6. What is Cross-Domain Content Duplication
Search engines support for using the rel=”canonical” link element across different websites across different domains (like as main domain, the subdomain, and other domains on the server). Similarly, the duplicate content that appears on the cross-domain URLs, for example.
- https://www.twinztech.com/difference-between-absolute-and-relative-urls/
- https://www.twinztech.com/blog/difference-between-absolute-and-relative-urls/
- https://blog.twinztech.com/difference-between-absolute-and-relative-urls/
- https://www.otherdomain.com/difference-between-absolute-and-relative-urls/
The above examples URLs shows the similar or identical content, this type of content on the web pages (page URLs) is said to be as Cross-Domain Content Duplication.
Read More:- Handling legitimate cross-domain content duplication
a) How to give Cross Domain Canonical tag URLs
There are two ways to give canonical tag on web pages to avoid duplicate content.
#1. The content should be own and not duplicate to the other page (page URL) content; the Canonical link element structure should give the same URL (protocol) on the page load. It should be applicable to cross domains on your website. See the below example.
#2. The content should not include your own and copy or duplicate from the other site page (page URL) content; the Canonical link element structure should give the path of the copied page URL (protocol) where you are copied from that URL should be taken as the canonical link. The below example process represents how to avoid the Cross-Domain Content Duplication.
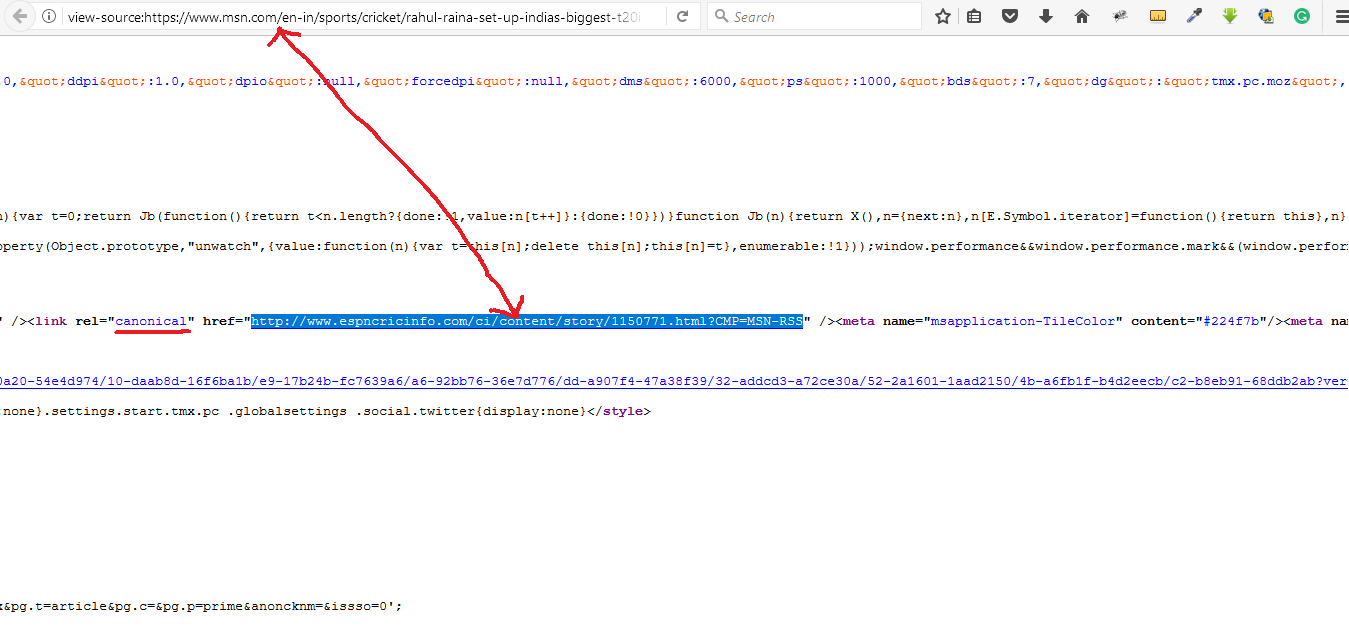
The above example represents the canonical URL of the other site in which the content is the copier or duplicate from other sites. In this way, we can tell search engines to which is the original content page URL.
b) Which URL does Google consider canonical (or duplicate)?
Based on the Index Status report to determine which page URLs are considered as a canonical or duplicate. Duplicates page URLs will be marked as invalid, and the canonical page URLs will be marked as valid.
The rel=”canonical” tag added pages considered as original (valid page URLs) and not specified pages are considered as duplicate(invalid page URLs).
Note: Even if you specified a canonical page, Google might pick a different canonical for various reasons based on the content.
7. The Impacts of Duplicate Content
- Without original or unique content, it is difficult for a search engine to identify what version of the duplicate content is the most trustworthy.
- Due to Duplicate, content search engines can slow down in finding new or original content.
- Search engines don’t know which version to either include or exclude from their indexes.
- Original or unique content is one of the key factors of the search engines (Google). Due to duplicate content, it will be the effect on SEO rankings.
- Due to Duplicate page content, the trust flow and page authority of the site will be decreased.
- Due to Duplicate or copy content loses the Search engine rankings and marketing values will be decreased.
8. How to Identifying Duplicate Content
- Web Search via Search Operators like site:twinztech.com see the examples on (https://support.google.com/websearch/answer/2466433?hl=en).
- Google Search Console is a powerful tool for identifying duplicate content. Go into the Search Console for your website and then go to Search Appearance » HTML Improvements, looking specifically for duplicate page titles and meta descriptions.

- Crawling the site by using SEO tools, such as ScreamingFrog and DeepCrawl, to identify duplicate page titles and content.
- Navigating through the website also find the duplicate or copy content.
9. Sources of Duplication
- Page Pagination URLs
- Comment Pagination URLs
- Duplicate URLs (search query parameters, session IDs, and Tracking IDs)
- Web Sorting (Filtering the data)
- Cross-Categories Pages (For an example: Having one Apple page is listed under the Fruits category page and having another Apple page is listed under the Pome Fruits category page.)
- Cross-Tags Pages (For an example: Having one Apple page is listed under the Fruits tag page and having another Apple page is listed under the Pome Fruits tag page.)
- Cross-domain URL, sub-domain URL, and subfolder URL duplication
- Website Search Functionality Results (URL strings or URL query parameters)
- Internet Protocols (HTTP vs HTTPS URLs, www vs non-www versions URLs and with or without forward slash of the domain)
- Website’s Printer-friendly and Mobile-friendly versions of page content.
10. Duplicate Content Solutions
- 301 redirections
- Using of rel=”canonical” tags for page URLs.
- Using of rel=”prev/next” tags for pagination URLs.
- Using of hreflang=”en-US” tags for language page URLs.
- With the help of search engines parameters handling features like Search Console and Webmaster Tools
11. General Guidelines by google webmasters
General Guidelines by google webmasters was explained about:
- Where we can use canonical
- How to deal with HTTPS pages
- Where we can ignore dynamic parameters
- How to add redirections from the HTTP to HTTPS pages.
- How to deal with SSL/TLS certificate for implementing canonicalization methods
You should follow the general guidelines, for all canonicalization methods on (https://support.google.com/webmasters/answer/139066)
Can I use a relative path to specify the canonical?
Yes, we can. Google and other search engines will recognized relative path URLs for an example

12. What if the rel=”canonical” returns a 404?
Google will continue to index your content and it has an algorithm to find a canonical, but we it recommends that you specify existing URLs as canonicals.
NOTES:
1. Google doesn’t get angry and penalizes to have duplicate content on the website. It’s not that they would demote a site for having a lot of duplicate content.
2. Source From (https://webmasters.googleblog.com/2009/02/specify-your-canonical.html)
Google currently will take canonicalization suggestions into account across subdomains (or within a domain), but not across domains. So site owners can suggest www.example.com vs. example.com vs. help.example.com, but not example.com vs. example-widgets.com.
Also Read : Robots.txt File vs Robots meta tag vs X-Robots-Tag
Blockquote tag
The link tag with the rel=”canonical” attribute avoid whole page “Duplicate Content” and cross-domain content duplication.
The Blockquote tag with the cite=”https://www.example.com” attribute is the great thing is that you can mark a small part of the page as taken from the other side, which the Search engines consider blockquote content should not be counted as original content.
HTML5 Blockquote tag is Beneficial
Many Top Sites using Blockquote tag with the cite=”https://www.example.com” attribute for avoiding the small portion of the snippet or duplicate content which is taken from the other site.
I’m not sure that if you know, but there’s a Blockquote tag with the cite attribute in HTML5, which I believe only will be positive for your search engine rankings.
For an Example
<blockquote cite=”https://www.worldwildlife.org/about/”>
The world’s leading conservation organization, WWF works in 100 countries and is supported by more than one million members in the United States and close to five million globally.
</blockquote>
Helpful Resources:
1. How to Flush The Rewrite Rules or URL’s or permalinks in WordPress Dashboard?
2. 16 Best Free SEO WordPress plugins for your Blogs & websites
3. What is an SEO Friendly URLs and Best Permalink Structure for WordPress?
4. 16 Most Important On-Page SEO Factors To Boost Your Ranking Faster in Google
5. 16 Best (free) AMP – (Accelerated Mobile Pages) WordPress Plugins
How AI Is Reshaping Digital Marketing Strategies in 2026

Maximizing ROI with HCI: Real‑World Benefits for IT Leaders

Search Atlas: What the Platform Does and Why It Leads in Local SEO
How Alert Fatigue Is Increasing Cyber Risk

How Apps Can Make Employee Communication A Lot More Simple

The Global Awakening: Understanding Gen Z’s Voice 🌍🎤

Canva AI: Your Creative Co-Pilot, Explained 🎨🤖

DALL·E AI: Redefining Creativity with Artificial Intelligence 🎨🤖

Runway ML: The Future of AI-Powered Creativity 🎥✨

🎨 Midjourney: The Complete Guide to AI Art Generation in 2025
Buy IG likes and buy organic Instagram followers: where to buy them and how?

100% Genuine Instagram Followers & Likes with Guaranteed Tool

7 Must Have Digital Marketing Tools For Your Small Businesses
Instagram Followers And Likes – Online Social Media Platform

Use of 3D Printing in Injection Molding
Top 25 Best SolarMovie Alternatives Updated List

13377x Original Site: 1337x Official Site, Proxy Sites, Movies, Torrents

Principles of Good Software Engineering

How To Get Started With Artificial Intelligence

Tamilrockers Alternatives: TamilRockers Proxy and Mirror Sites [working]
-
Instagram5 years ago
Buy IG likes and buy organic Instagram followers: where to buy them and how?
-
Instagram5 years ago
100% Genuine Instagram Followers & Likes with Guaranteed Tool
-
Business7 years ago
7 Must Have Digital Marketing Tools For Your Small Businesses
-
Instagram6 years ago
Instagram Followers And Likes – Online Social Media Platform